AI / Extract text from image or PDF (AI-OCR)

Home > User guide > BOT > How to use the BOT editor > Extention> AI > Extract text from image or PDF (AI-OCR)
App overview
Use AI-OCR to convert images or PDFs into text and extract table data or text from specified coordinates.
| Extended Feature URL | cbot-extension://cloud-bot:ai:recognize-image:4 |
| Provider | Cloud BOT official |
| External communication | Yes *This application communicates with Azure Cognitive Services API. |
| Version | 4 |
| Transaction | Use a transaction for each extraction. 3 transactions per page |
Screen description
Input screen
Extract option
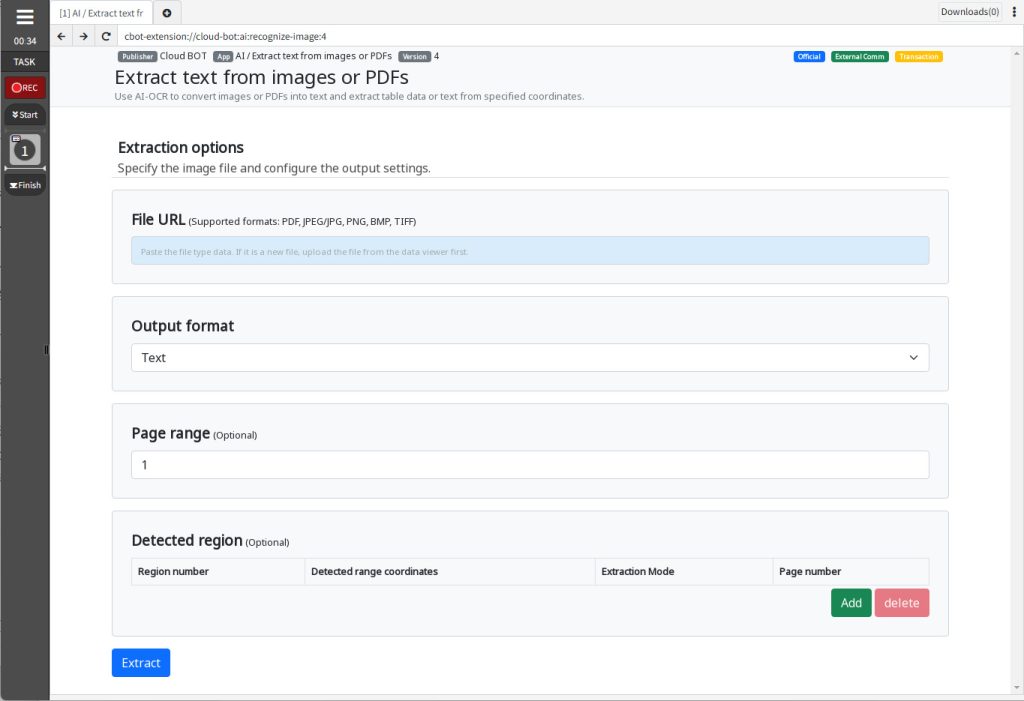
File URL
Specify the URL where the file from which the text extraction is to be performed is located.
(Supported formats:PDF,JPG/JPG,PNG,BMP,TIFF)
Output format
Specifies the output format of the text.
- Text: Output the extraction results as a single text data.
- Layout: Classifies the extraction results into specific categories and outputs them.
- JSON: Output the extraction results in json format.
Data categories to output (Output format:Displayed only when 'Layout' is selected)
Specify the 'Data category' to be displayed on the results screen.
*For more information on data categories, please click here.
Attributes information to output (Output format:Displayed only when 'Layout' is selected)
Specifies 'Attribute information' to be displayed on the results screen.
*For more information on data attributes, please click here.
Page range (Option)
Specifies the page from which text extraction is performed.
* You can specify multiple pages to be extracted, separated by commas (,). (ex: 1,2,5)
* The number of pages to be extracted can be specified with a hyphen (-). (ex: 3-6)
* If an empty value is specified, all pages are covered.
Detected region (Option)
Specify Detected region. Detected only from the specified Detected region.
* Specifying the Detected region is optional.
* You can increase or decrease the Detected region by clicking the Add or Delete button. A maximum of 10 region can be set.
In order to specify coordinates accurately, the coordinates to be specified must be detected and confirmed in advance.
For more information on specific methods, please click here.
[Region number]
Numbers from 1 to 10 are assigned in sequence.
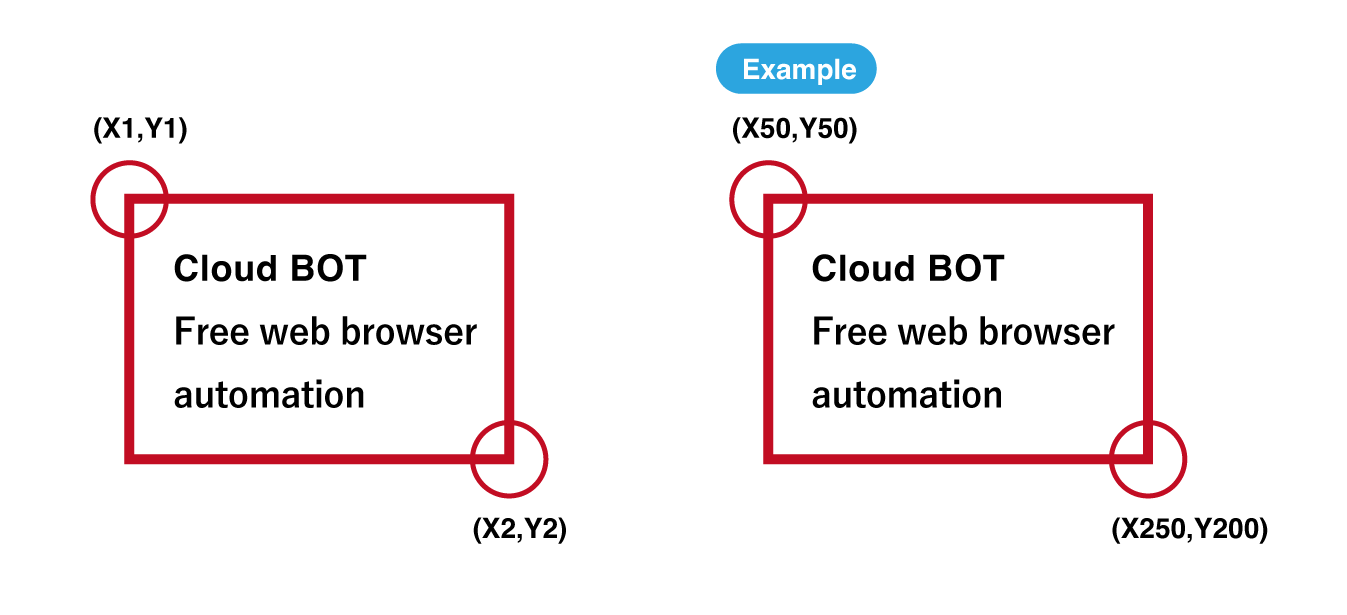
[Detected range coordinates]
Detected range coordinates can be specified.
Coordinates are expressed as a rectangle with two corner points, upper left and lower right. For example, for 50,50,250,200, X1=50, Y1=50, X2=250, Y2=200.
[Extraction mode]
Select Extraction mode.
Extract information over lapping with the range: Extracts all information that overlaps the Detected range coordinates.
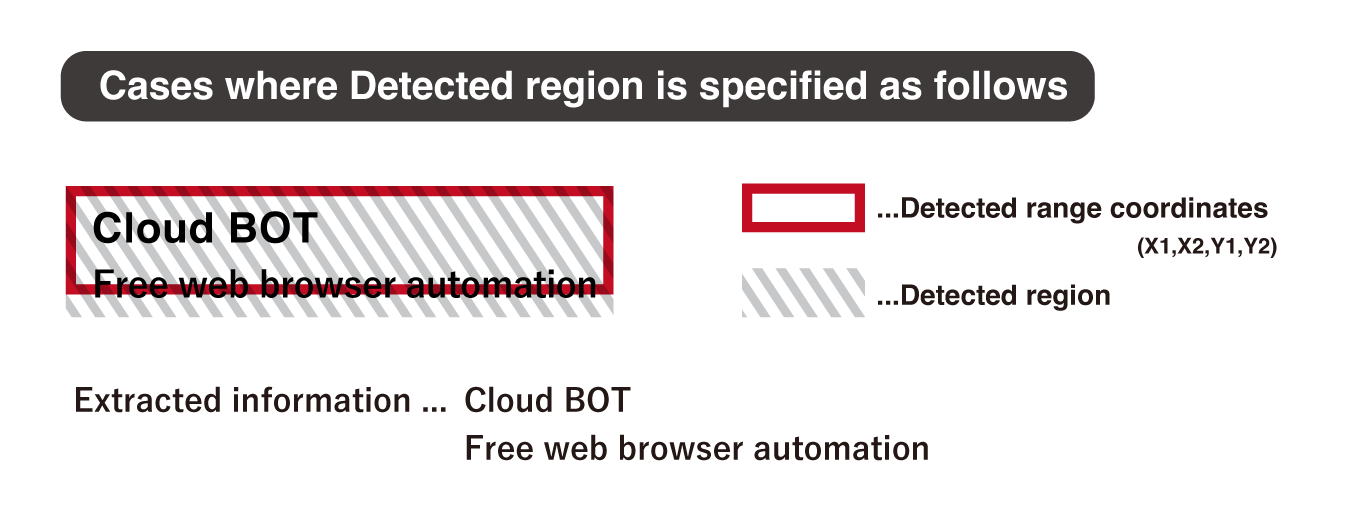
Extract information contained within the range: Only information that falls within the Detected range coordinates is extracted.

[Page number]
Specifies the page number.
Result screen
The extraction is complete.
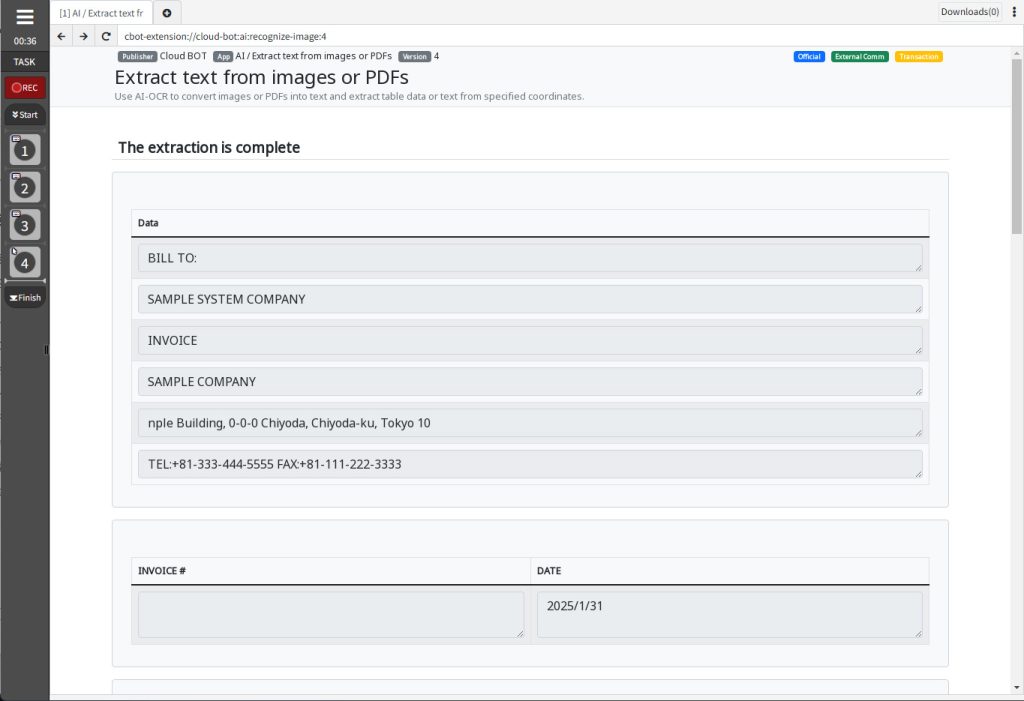
Extraction results are displayed.
Output Format: Additional explanation of "Layout"
When a layout is selected, the extracted results are sorted into the following data categories: "Table," "Title," "Section Heading," "Footnote," "Header," "Footer," "Page number," "Barcode," and "No category" and output.
*AI will automatically determine which data category the extracted data will be classified into.
When "Attributes information to output" is specified, data attribute information such as "Data category" and "Page number" and "Detected region number" can be output to the Extraction Result screen.
The coordinates of the detected text are also displayed by specifying "Detected rectangle".
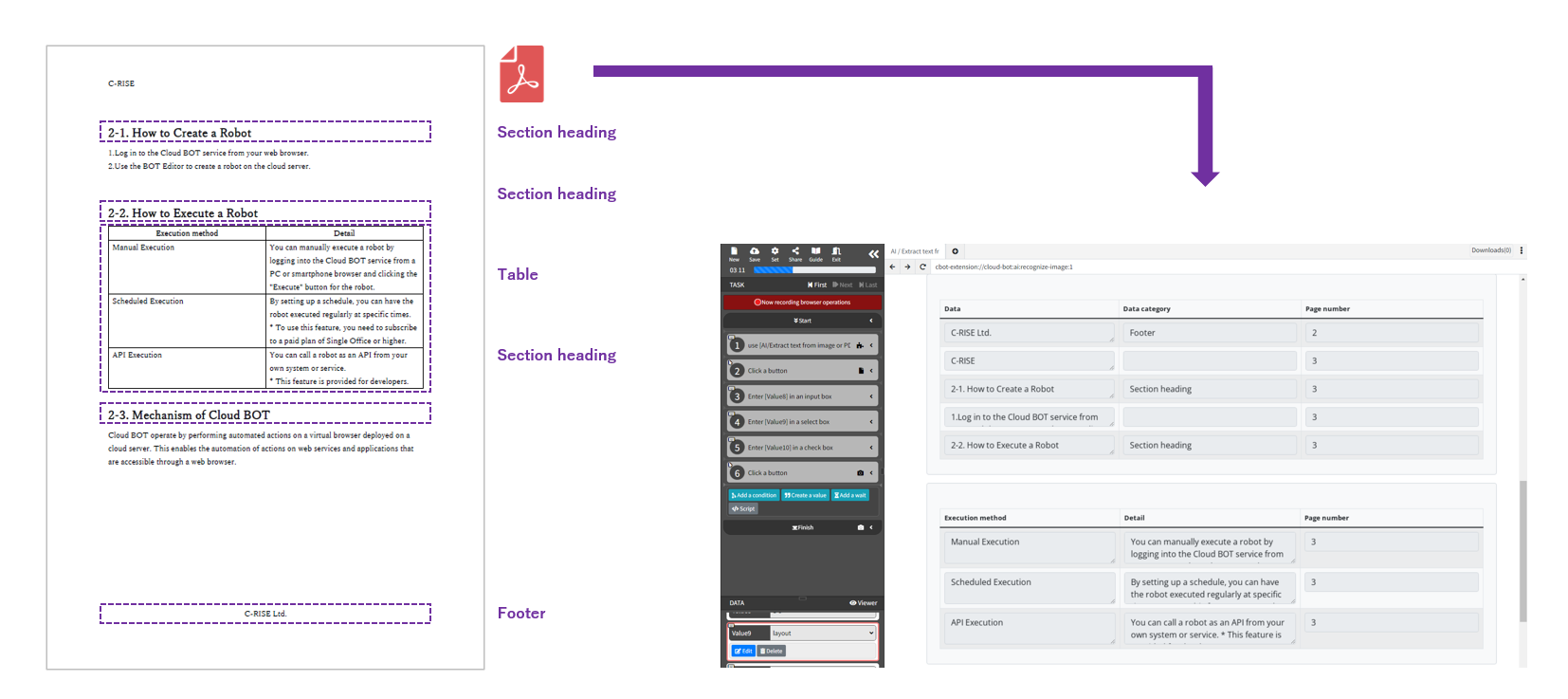
* Only when the data category is "Table", only "page number" will be output as attribute information.
Attributes information to output: Additional explanation of "Detected rectangle"
When "Detected rectangle" is specified in "Attributes information to output", the coordinates of the detected text are displayed. The coordinates detected at this time can be used in the "coordinates" field of the "Detected region" input screen.
The detection methods are as follows.
1. Open a Virtual browser. (*It is not necessary to record the task.)
2. Open the "Extract text from image or PDF" extension.
3. Upload a file or specify a URL.
4. Select "Layout" as output format.
5. When "Attributes information to output" is displayed, specify "Detected rectangle".
6. The coordinates will be detected in the result display screen.
7. The detected coordinates can be copied to the clipboard.