AI / 画像やPDFからテキストを抽出する (AI-OCR)

ホーム > ユーザガイド > BOT > BOTエディタの使い方 > 拡張機能 > AI > 画像やPDFからテキストを抽出する (AI-OCR)
アプリ概要
AI-OCRにより、画像やPDFをテキスト化し、表データや指定座標位置のテキストを抽出します。
| 拡張機能URL | cbot-extension://cloud-bot:ai:recognize-image:4 |
| 提供元 | Cloud BOT official |
| 外部通信 | あり *このアプリはAzure AI Document IntelligenceのAPIと通信を行います。 |
| バージョン | 4 |
| トランザクション | 抽出毎にトランザクションを使用します。 1ページあたり3トランザクション |
画面説明
入力画面について
抽出オプション
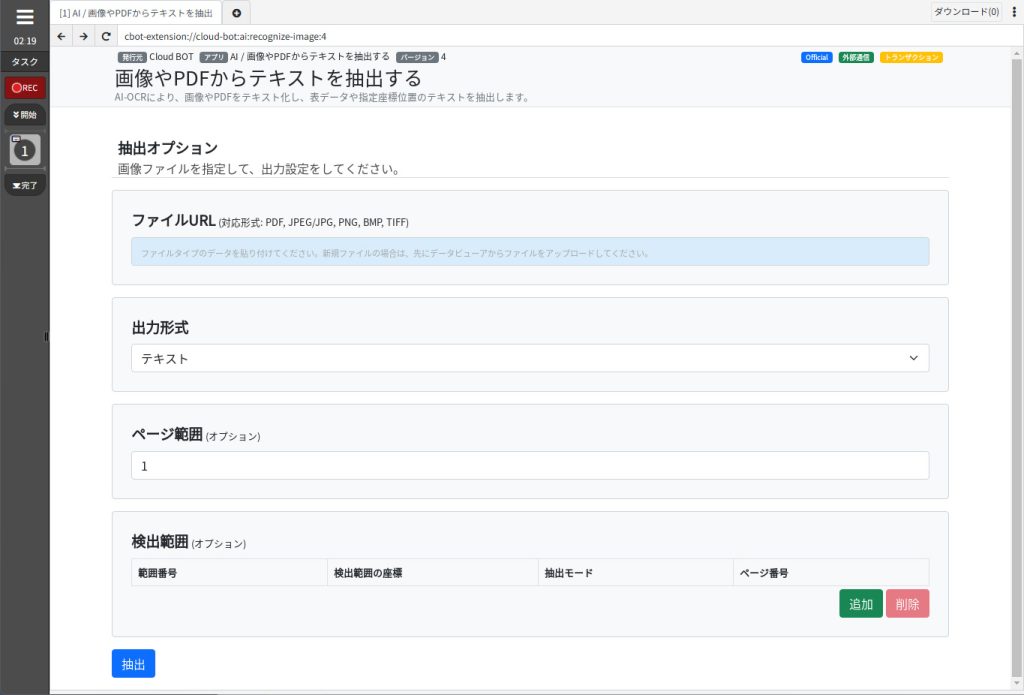
ファイルURL
テキスト抽出を行うファイルを指定します。
(対応形式:PDF,JPG/JPG,PNG,BMP,TIFF)
出力形式
テキストの出力形式を指定します。
- テキスト: 抽出結果を1つのテキストデータとして出力します。
- レイアウト: 抽出結果を特定の区分に分類し、出力します。
- JSON: 抽出結果をjson形式で出力します。
出力するデータ区分 (出力形式:レイアウト選択時のみ表示)
結果画面に表示するデータ区分を指定します。
※データ区分については、こちらをご参照下さい。
出力する属性情報 (出力形式:レイアウト選択時のみ表示)
結果画面に表示する属性情報を指定します。
※属性情報については、こちらをご参照下さい。
ページ範囲 (オプション)
テキスト抽出を行うページを指定します。
※抽出対象のページ数をカンマ(,)区切りで複数指定できます。(例: 1,2,5)
※抽出対象のページ数をハイフン(-)で範囲指定できます。(例: 3-6)
※空値を指定すると全ページが対象となります。
検出範囲 (オプション)
検出範囲を指定します。指定した検出範囲からのみ検出します。
※追加、削除ボタンをクリックすることで、検出範囲を増減できます。最大で10の範囲を設定できます。
また、座標を正確に指定するためには、あらかじめ指定したい座標を検出し、確認しておく必要があります。
具体的な方法についてはこちらをご覧ください。
[範囲番号]
1から10までの番号が順に振り分けられます。
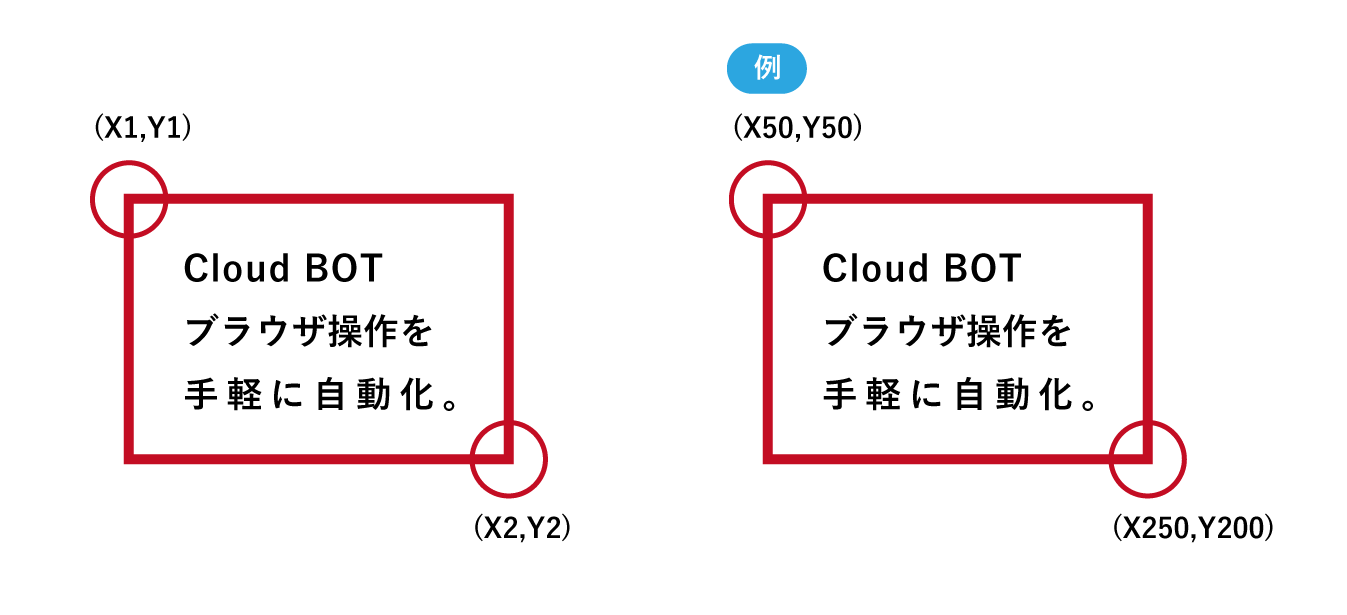
[検出範囲の座標]
検出範囲の座標を指定できます。
座標は、左上と右下のコーナー2点の四角形で表現します。例えば、50,50,250,200の場合は、X1=50、Y1=50、X2=250、Y2=200となります。
[抽出モード]
抽出モードを選択します。
範囲に重なる情報を抽出:検出範囲の座標に重なる情報すべてを抽出します。
範囲内に収まる情報を抽出:検出範囲の座標内に収まる情報のみを抽出します。
[ページ番号]
ページ番号を指定します。
結果表示画面について
抽出完了しました。
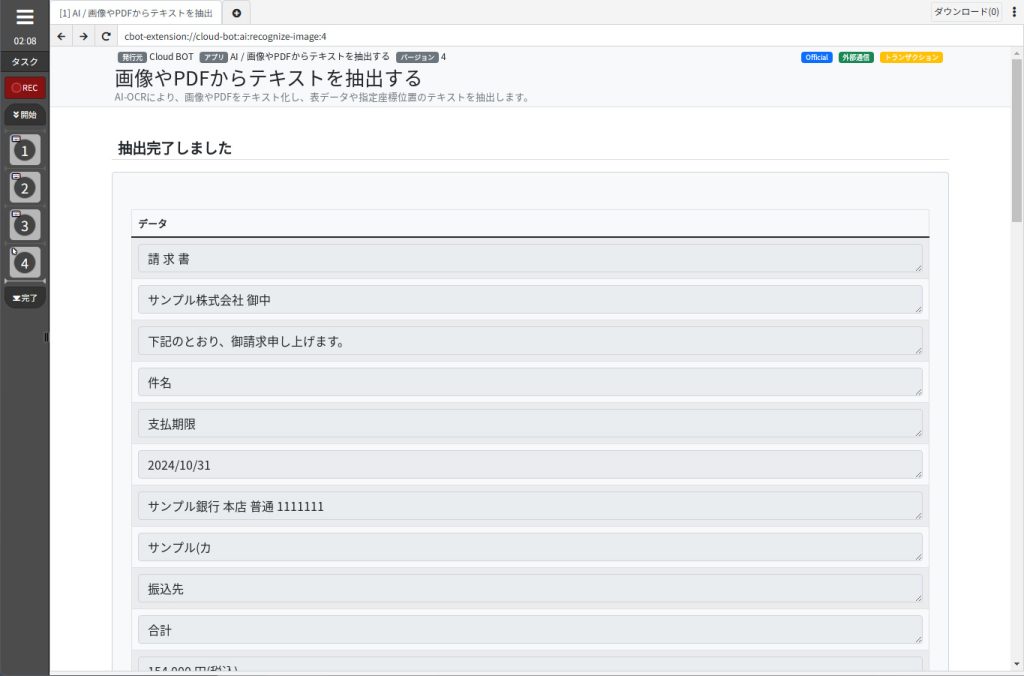
抽出結果が表示されます。
出力形式:"レイアウト"についての補足説明
レイアウトを選択すると、抽出結果を"テーブル"、"タイトル"、"セッションの見出し"、"脚注"、"ヘッダー"、"フッター"、"ページ番号"、"バーコード"、"区分無し"のデータ区分に分類し、出力します。
※抽出されたデータがどのデータ区分に分類されるかはAIの自動判断になります。
"出力する属性情報"を指定することで、データの属性情報である"データ区分"や"ページ番号"、 "検出範囲番号"を結果表示画面に出力することができます。
また、"検出座標"を指定することで、検出されたテキストの座標が表示されます。
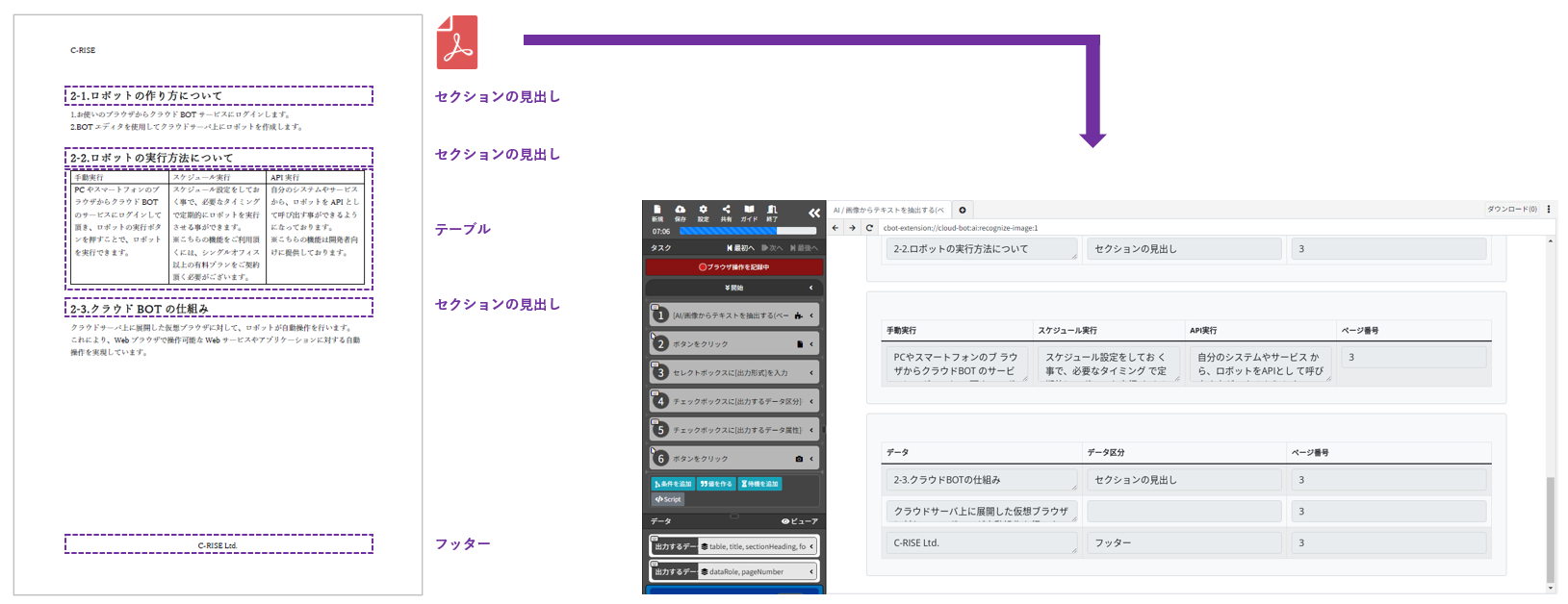
※データ区分が"テーブル"の場合に限り、属性情報は"ページ番号"のみが出力されます。
出力する属性情報:"検出座標"についての補足説明
"出力する属性情報"の"検出座標"を指定することで、検出されたテキストの座標が表示されます。ここで検出された座標は入力画面の"検出範囲"の"座標"に使用できます。
検出方法は以下です。
1. 仮想ブラウザを開きます。(*タスクを記録する必要はありません。)
2. 拡張機能"画像やPDFからテキストを抽出する"を開きます。
3. ファイルをアップロード、もしくはURLを指定します。
4. 出力形式で"レイアウト"を選択します。
5. "出力する属性情報"が表示されたら"検出座標"を指定します。
6. 結果表示画面に座標が検出されます。
7. 検出された座標をクリップボードにコピーできます。