AI / 画像やPDFから指定位置のテキストを抽出する (AI-OCR)

ホーム > ユーザガイド > BOT > BOTエディタの使い方 > 拡張機能 > AI > 画像やPDFから指定位置のテキストを抽出する (AI-OCR)
アプリ概要
AI-OCRにより、定型フォーマットのドキュメントからテキストを抽出します。雛形ドキュメントをもとに抽出設定を行います。
| 拡張機能URL | cbot-extension://cloud-bot:ai:recognize-image-marker:3 |
| 提供元 | Cloud BOT official |
| 外部通信 | あり *このアプリはAzure AI Document IntelligenceのAPIと通信を行います。 |
| バージョン | 3 |
| トランザクション | 抽出毎にトランザクションを使用します。 1ページあたり3トランザクション |
定型フォーマットの同じ箇所のテキストを、複数のドキュメントから連続して抽出できます。
ドキュメントに記載されている一部のテキストを目印(マーカー)として定義し、そこからの相対位置により抽出対象のテキストを抽出します。
例
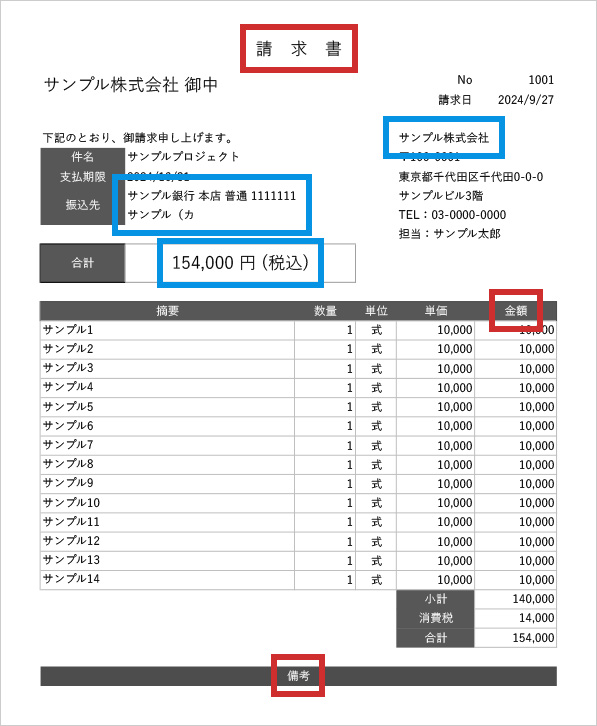
赤枠:マーカーとして定義するテキスト
複数のドキュメントにおいて記載内容と位置が変わらず、なるべく離れた位置にある複数のテキストをマーカーに指定する事で、画像やPDFがある程度傾いていても、目的のテキストを抽出できます。
青枠:抽出する位置
抽出するテキストは、定義されたマーカーからの相対位置で特定します。
事前設定
抽出定義情報の作成
マーカーと抽出位置を記録した抽出定義情報を予め作成します。
この抽出定義は一度作成して保管し、複数のドキュメントから連続してテキストを抽出する際に使用します。
この設定は、抽出定義情報を取得するために行うので、BOTとして保存する必要はありません。
抽出方法(定義設定)
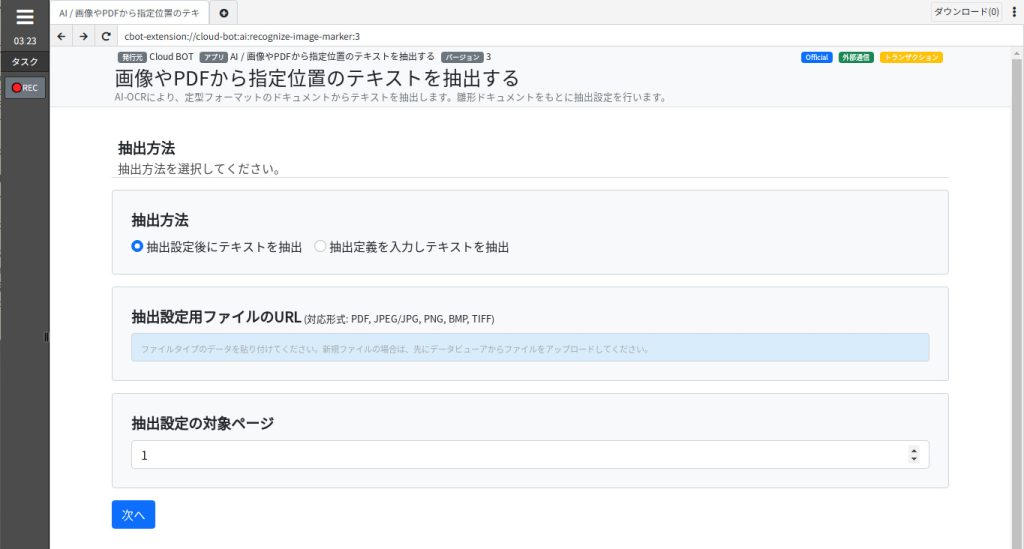
抽出方法
抽出方法を指定します。
抽出定義を設定する場合は「抽出設定後にテキストを抽出」を選択します。
抽出設定後にテキストを抽出:雛形ドキュメントをもとに抽出設定を行い、その定義を使用してテキストを抽出します。
抽出定義を入力しテキストを抽出:抽出定義を入力してテキストを抽出します。
抽出設定用ファイルのURL
雛形となるドキュメントファイルを指定します。
(対応形式:PDF,JPG/JPG,PNG,BMP,TIFF)
抽出設定の対象ページ
雛形ドキュメントから抽出設定を行う対象ページを指定します。
抽出設定(定義設定)
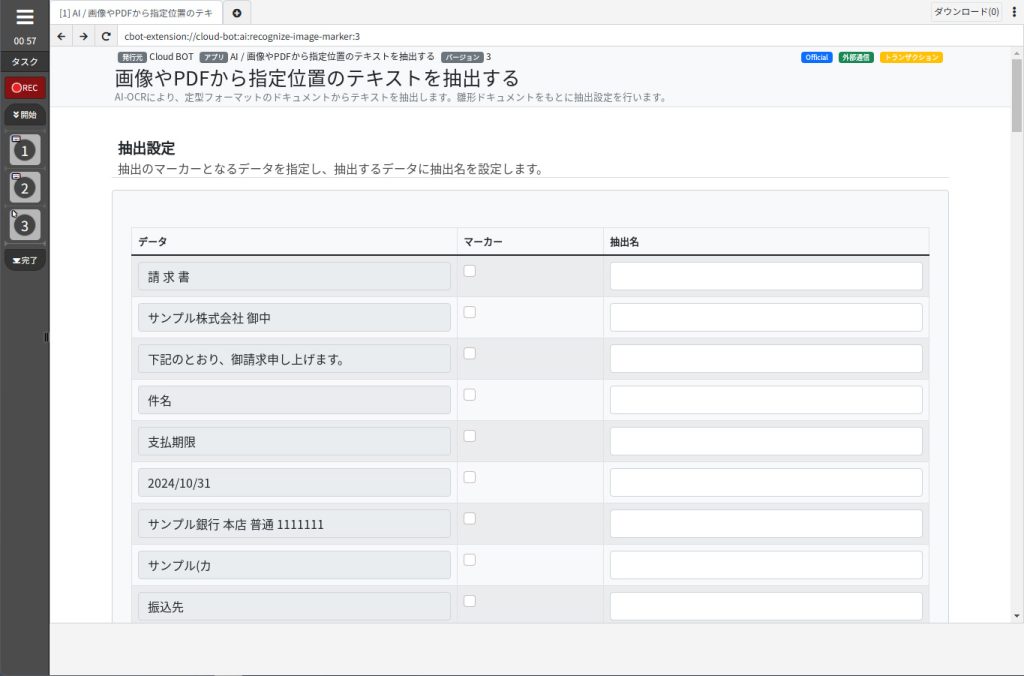
[データ]
雛形ドキュメントから抽出したテキストが表示されます。
[マーカー]
チェックを入れる事で、そのテキストを目印にして抽出したいテキストとの位置関係を定義情報にします。
[抽出名]
抽出したいテキストに対してデータ名を指定します。
抽出オプション(定義設定)
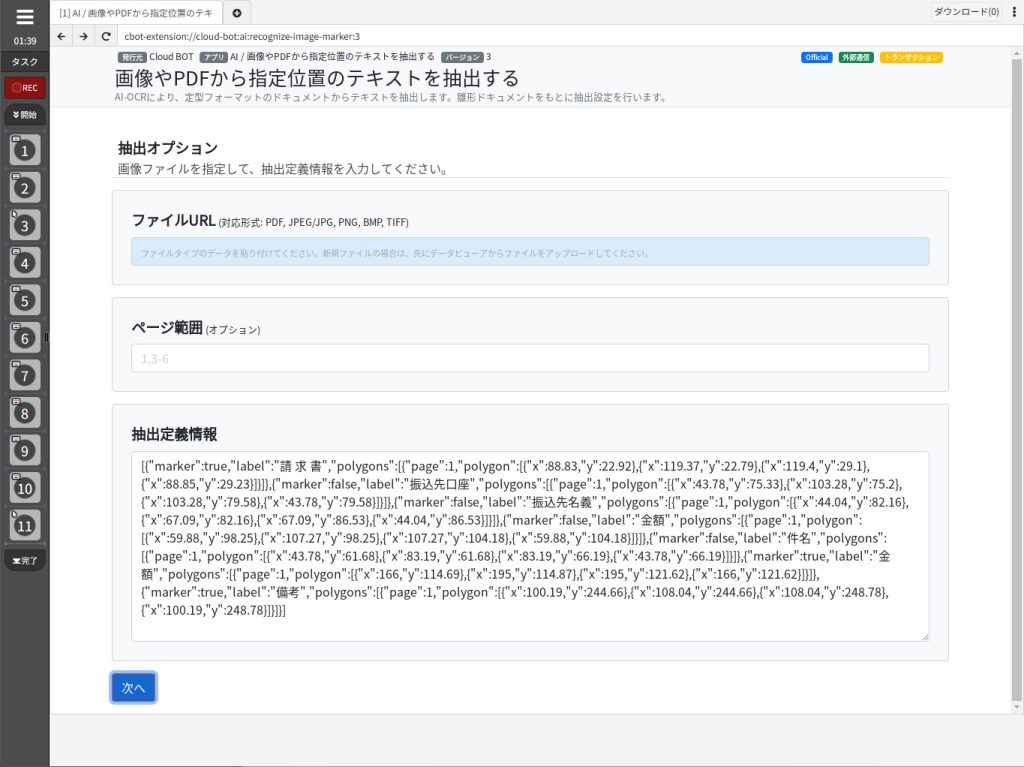
抽出定義情報が作成されます。
作成された情報が正しく動作するか、続けて検証できます。
ファイルURL
テキスト抽出の検証を行うファイルを指定します。
(対応形式:PDF,JPG/JPG,PNG,BMP,TIFF)
ページ範囲 (オプション)
テキスト抽出の検証を行うページを指定します。
※抽出対象のページ数をカンマ(,)区切りで複数指定できます。(例: 1,2,5)
※抽出対象のページ数をハイフン(-)で範囲指定できます。(例: 3-6)
※空値を指定すると全ページが対象となります。
抽出定義情報
抽出設定により作成した定義情報です。
この情報を使用して、定型フォーマットのドキュメントからテキストを抽出します。
画面説明
入力画面について
予め作成した抽出定義情報を使用して抽出を行います。
この操作には抽出定義情報が必要です。
抽出方法
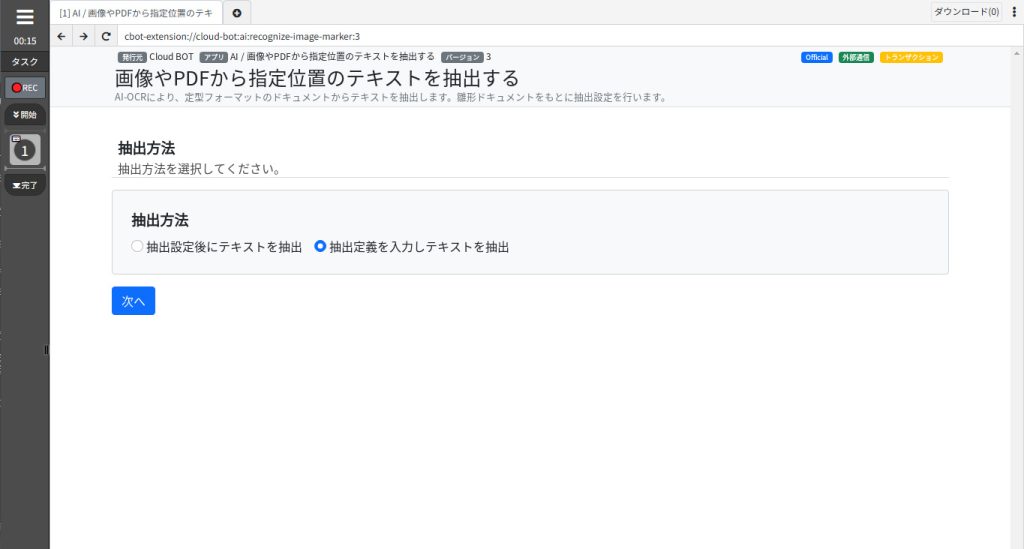
抽出方法
抽出方法を指定します。
ドキュメントからテキストを抽出する場合は「抽出定義を入力しテキストを抽出」を選択します。
抽出オプション
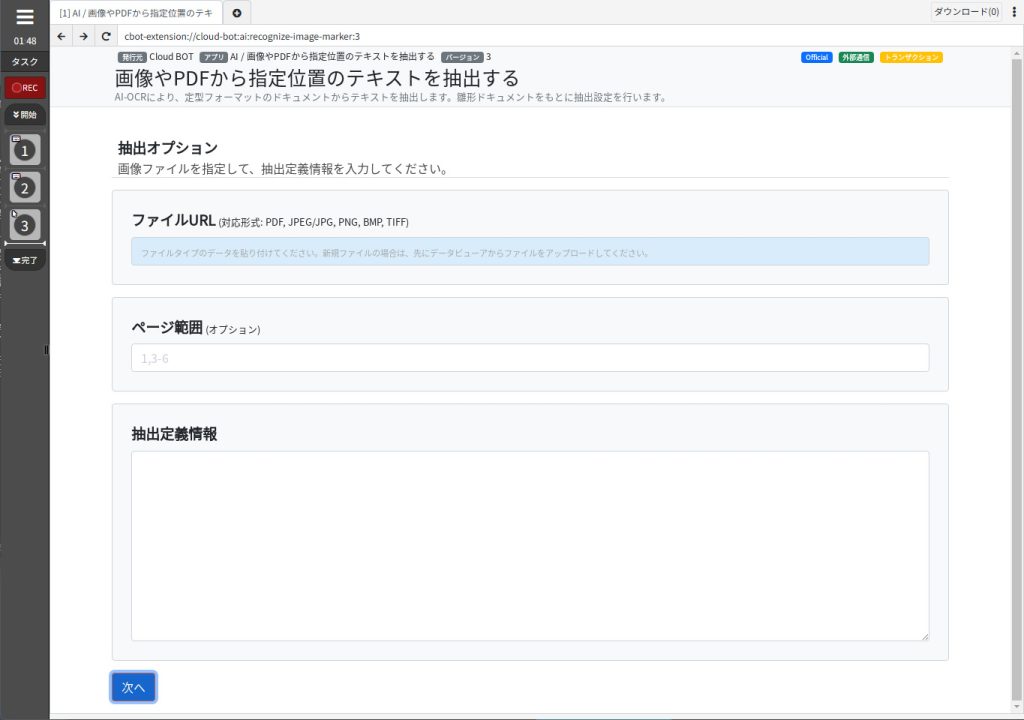
ファイルURL
テキスト抽出を行うファイルを指定します。
(対応形式:PDF,JPG/JPG,PNG,BMP,TIFF)
ページ範囲 (オプション)
テキスト抽出を行うページを指定します。
※抽出対象のページ数をカンマ(,)区切りで複数指定できます。(例: 1,2,5)
※抽出対象のページ数をハイフン(-)で範囲指定できます。(例: 3-6)
※空値を指定すると全ページが対象となります。
抽出定義情報
抽出設定した定義情報を指定します。
*抽出設定についてはこちら。結果表示画面について
抽出完了しました。
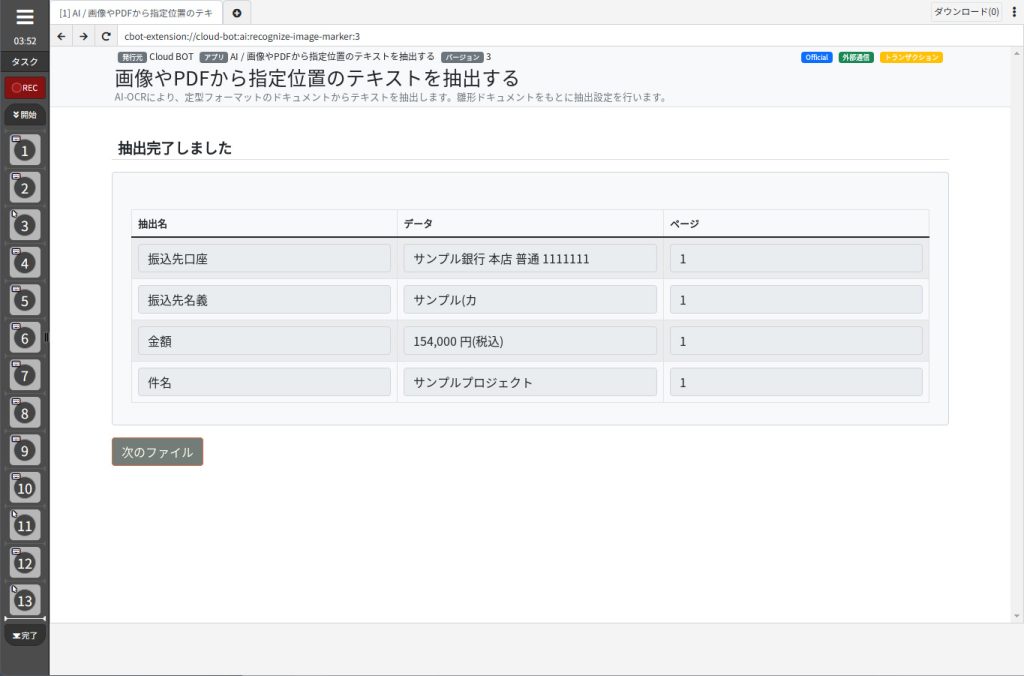
抽出結果が表示されます。
「次のファイル」を押す事で連続してファイルを処理できます。